在数字化转型浪潮席卷全球的今天,数据已成为企业最核心的资产和驱动创新的引擎。如何高效、可靠地管理和利用海量、多源、异构的数据,是众多企业面临的共同挑战。传统的“数据仓库”与“数据湖”架构各有优劣,但往往难以满足现代企业对数据处理的敏捷性、灵活性和实时性的综合要求。在此背景下,“湖仓一体化”数据处理服务应运而生,它作为数字化转型的数据底座,正以其独特优势重塑企业的数据处理范式。
一、湖仓一体化:数据架构的演进与融合
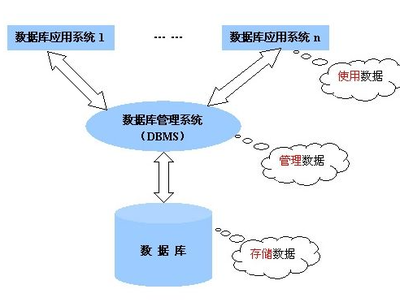
“湖仓一体化”并非简单的技术叠加,而是数据仓库与数据湖优势的深度整合与演进。传统数据仓库以其强大的结构化数据处理能力、严格的数据治理和高效的查询性能著称,但面对半结构化和非结构化数据时往往力不从心,且架构相对封闭,扩展成本高昂。数据湖则以开放、低成本的方式存储海量原始数据(包括日志、图片、音视频等),提供了极大的灵活性,但常因缺乏有效的数据治理而沦为“数据沼泽”,查询与分析性能也难以保障。
湖仓一体化架构旨在打破这一藩篱。它在底层保留了数据湖低成本、开放存储原始数据的能力,同时在其上构建了类似数据仓库的结构化数据管理与高性能计算引擎。这就像一个兼具“湖”的广阔包容与“仓”的井然有序的“智慧水库”,实现了数据从原始摄入、灵活探索到规范治理、高效分析的无缝流转。
二、作为数据底座的核心价值
在数字化转型中,稳固、智能的数据底座是支撑上层业务应用(如精准营销、智能风控、供应链优化等)的基石。湖仓一体化数据处理服务作为新一代数据底座,其核心价值体现在:
- 统一存储,消除数据孤岛:为企业提供了一个统一的数据存储层,能够原生支持结构化、半结构化和非结构化数据,打破部门与系统间的壁垒,实现全域数据的汇聚,为全局数据洞察奠定基础。
- 灵活性与敏捷性并重:数据科学家和业务分析师可以在同一平台上,对原始数据进行自由的探索性分析(数据湖模式),而经过清洗、加工后的高质量数据又能被迅速组织成主题域,供业务部门进行稳定、高效的联机分析处理(数据仓库模式),极大加速了从数据到价值的转化过程。
- 成本与性能的优化平衡:通过分层存储和智能数据管理策略,将热数据、温数据、冷数据分别置于不同性能/成本的存储介质上,并利用现代计算引擎(如Spark、Flink、Presto等)实现计算与存储的解耦与弹性伸缩,在控制总体拥有成本(TCO)的同时保障关键业务的查询性能。
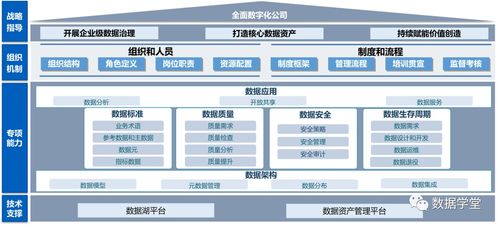
- 强化数据治理与安全:在统一的架构下,可以更便捷地实施贯穿数据全生命周期的元数据管理、数据质量监控、数据血缘追溯以及统一的访问权限控制和审计,确保数据的可信、可用与安全合规。
三、数据处理服务:赋能业务创新的关键一环
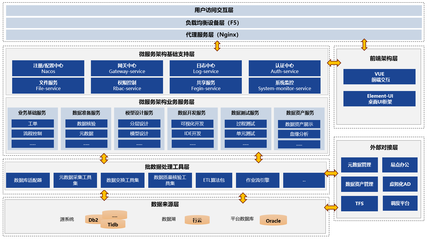
湖仓一体化不仅是技术架构,更需要以“服务”的形式交付,才能真正赋能业务。现代数据处理服务通常涵盖:
- 数据集成与实时同步服务:提供批流一体的数据接入能力,轻松对接各类数据库、日志、IoT设备及SaaS应用,实现数据毫秒级至分钟级的低延迟入湖。
- 数据开发与治理平台:提供可视化、拖拽式的数据开发IDE,支持SQL、Python等多种开发范式,内置任务调度、数据质量规则、血缘分析等治理工具,降低开发门槛,提升协作效率。
- 统一的数据服务与API管理:将处理后的数据资产(如数据表、指标、模型)以API、数据服务或数据产品的形式发布,供下游应用系统或数据分析工具消费,实现数据价值的便捷输出。
- AI与机器学习集成:无缝集成主流的机器学习框架和算法库,直接在数据底座上进行模型训练、评估和部署,缩短AI项目从实验到生产的路径。
四、展望与挑战
随着云原生、存算分离、智能运维等技术的深度融合,湖仓一体化数据处理服务将变得更加弹性、智能和自动化。它将成为企业构建实时、智能数据驱动的运营体系不可或缺的基础设施。
成功的落地也面临挑战:企业需要根据自身业务特点和数据规模进行合理的架构设计与技术选型;需要培养既懂业务又懂数据的复合型人才;更需要从组织和文化层面,推动跨部门的协同与数据共享意识的建立。
在数字化转型的深水区,以湖仓一体化为核心的现代化数据处理服务,正为企业夯实数据这一“新生产要素”的管理与利用根基。它不仅是技术的升级,更是思维与模式的变革,引领企业驶向数据驱动决策与创新的广阔蓝海。